Analysing Cross-Lingual Transfer in Low-Resourced African Named Entity Recognition
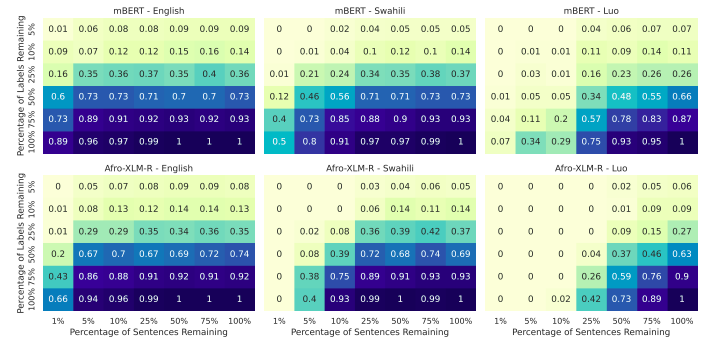
Have you ever wondered which properties of a language help transfer learning in a low-resourced settings?
Have you ever wondered which properties of a language help transfer learning in a low-resourced settings?
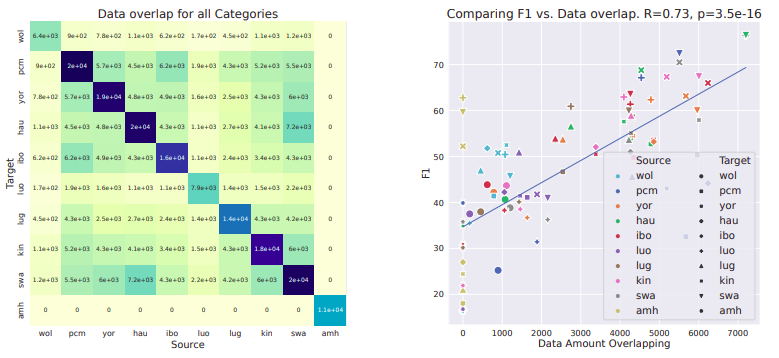
We all know that data quality is important, but how important is it with respect to quantiy? We provide a systematic analysis of this question on named-entity recognition for low-resourced languages.
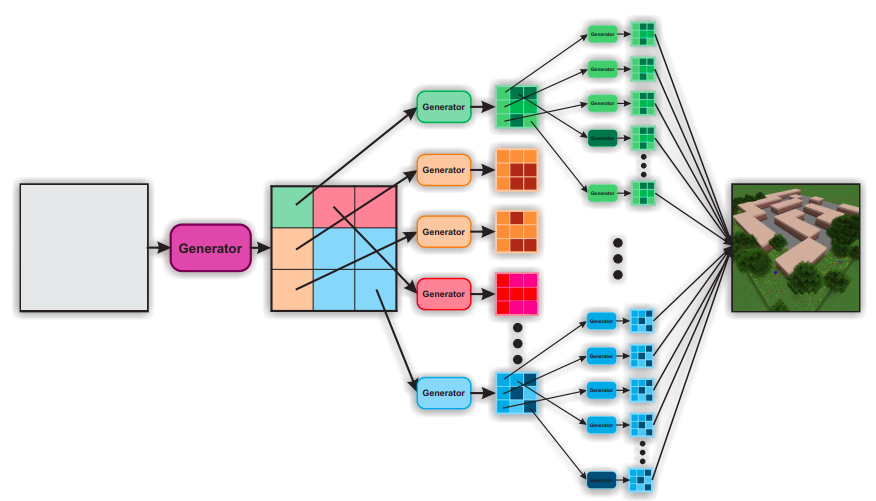
We composet level generators hierarchically to create complex structures easily.
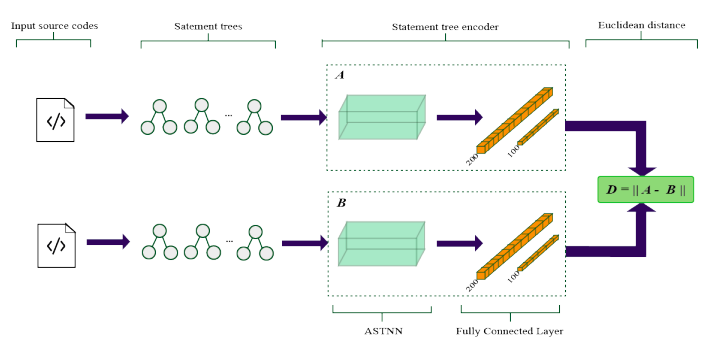
We improve a source code similarity detection baseline by leveraging contrastive learning.